独立开发2.0:less intelligence,more structure
Manus爆火之后,他们团队总结出来一句话:Less structure,more intelligence.
但是我自己用了几个月的AI工具,加上读了各种各样的访谈纪要之后,我还是回归到了人本位:Intelligence是模型的,Structure是自己的。
我想通过自己使用AI工具的历程,论证这句话。
我使用AI进行编程经历了如下阶段
-
过程型表达:一点一点给AI描述我想要什么、长什么样子,让它一点一点堆砌功能。最终模型在过度的自由化之下崩溃,代码冗余,每次执行都在制造bug。
-
结构化表达:一次性把需求描述出来,但还是聚焦于业务内容。比过程表达好很多,但是也撑不住。由于是一次性完成,耦合度太高,一调就崩。
-
结构化+实例:明确要求模型使用什么前后端技术框架、设计组件库;把图片等信息丢给模型做参考;效率大幅度提升,已经可以做出demo了,但是稳定性很差,性能也不行。由于到目前为止都没看过代码,实际上已经成了屎山。
-
Rules+Mcp接入:开始学习rules,大概知道不单单要说明前后端用什么技术,还要做git、测试、注释、控制代码风格等等,最终抄了一份通用的;开始使用Mcp拆解任务为todo list、调用前端控制台信息直接处理。到此时,效率又上了一个台阶,更重要的是,通过学习rules,让我知道一个软件的稳定运行需要明确的规则和"环境"。
-
面向对象编程:由于只使用了徒有其表的rules,最终AI还是失控了,原因主要是它执行任务我就"同意",实际上没有帮它限制好边界,只靠一份rules、靠它自觉肯定是不够的。此时,我才真正去了解什么是"架构",有意识引导AI做功能解耦、前后端分离、流程与服务分离、逻辑方法抽象。结果是,代码终于稳住了,不会一损俱损了。
-
学会用库:这是一个重要的转变,遇到问题先搜资源库,搜不到再想办法。
-
终极自动化:将外部模型、人、编程AI融为一体,利用rules、memory、知识库,实现终极的"人负责structure,AI负责intelligence"。
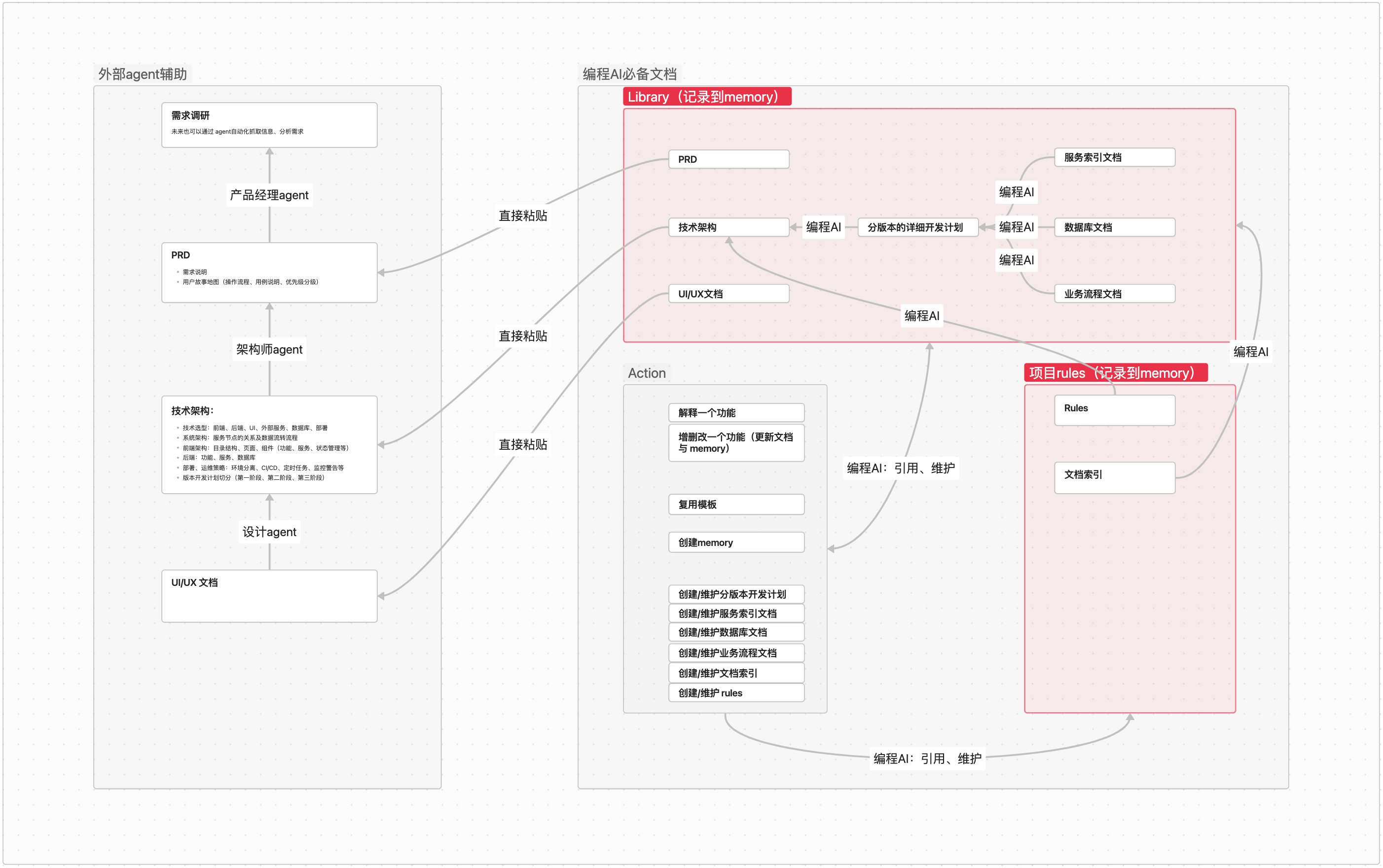
终极自动化架构展示
下面我直接放一下最后一部分的构建结果:
这套工具构建基于一些认知
Memory 和 Rules 的机制
- Memory
- 定义:模型确认完输入内容(交互输入+rules)之后会自动判定相关 memory,作为上下文信息自动注入任务之中
- 适合的内容:一些背景、业务逻辑、流程、知识
- 用法:手动或者交互命令都可以设置;不要太多条,10-20 条;每条不要太长,2-5 段比较好
- Rules
- 定义:Rules 是 AI 执行任务时输入信息的一部分,分为全局和项目。全局对所有项目生效,项目 rules 配置在项目的根目录之下,仅在项目内生效。项目 rules 是对全局 rules 的继承和具体化,AI 工作时会先看项目 rules,如果有对应的内容,就会覆盖全局 rules
- 适合的内容:明确的可执行项目,比如行为指令、代码规范、做什么不做什么(禁止在 XX 文件中使用 XX)
- 我的全局 rules:
- 之前我把 rules 当成了 library 来用,填写的内容分为很多条,包含:角色设定、架构设计原则、代码规范、注释文档规范、质量与可观测性、CI/CD 与依赖管理、用户体验注意事项等等
- 还写了一些零散规则:能修改文档就不要删除、重写文档,节约资源;具体功能设计以架构文档为准,PRD 仅作为需求背景了解;完成一个模块的变更,可以主动提取关键信息,压缩核心内容之后提交到 Memory 中
- 我的项目 rules:
- 一类是基础信息,包含架构和 PRD 等文件
- 一类是原则,根据架构文件,对全局规范的具体扩展
- 一类是 action,比如如何解释代码、如何修改功能,是 rules 的核心内容
- 使用问题:
- rules 如果太长就会被压缩,always 执行也不一定能按照规定执行。太多的 rules 反而会加重上下文的执行负担。实际使用中我就发现,全局 rules 执行不到位,比如我让它在创建文档的时候要先写一段文档说明,它就不执行
- 全局 rules 和项目 rules 的关系不太好说明,我原来理解的事情两个 rules 的内容维度是一样的,区别在于,项目 rules 是选定了技术框架之后,在全局 rules 维度上做的细化要求。但看样子这样做不太对,因为 AI 为了了解一个规则还需要从两边 rules 分别获取一部分信息再做加工,这明显是低效的
Memory 和 rules 的迭代用法
- 原则
- 不要期待完全智能的规则/上下文机制,靠得住的只有人,越复杂的项目越不能依赖这些机制
- 为了保证信息可控,自己要生产最全面的文档:PRD(需求说明及用户故事地图)、技术架构、mvp 版本功能详情、git/注释/代码风格/接口规范等方面的原则、功能变更记录、数据库文档、内外部服务索引文档(包含 API)、功能流程
- 将详细的文档压缩成 memory,分门别类计入 rules 和 memory
- 如何处理人、memory、rules 的分工
- Memory:包括 library 和 rules 文件夹的内容;Library 包括核心开发文件比如 PRD、设计、架构文件,以及服务、流程、数据库三个文档
- Rules:索引文档、项目规则
- 人:维护 action 文件夹,记录各个宏动作,通过这些动作来维护其他核心文档。比如让 AI 增加一个功能前要阅读 xx、要测试、要完成文档更新、记忆更新
- 如何写文档(为 AI 优化调用)
- 无论是文档、rules、memory,都要加上描述。这能快速帮助 AI 定位关键信息,节约 token,提高效率
- 对于压缩过的内容,要给出原文索引,使用@作为引导:"处理订单时,必须严格遵守订单状态机。状态定义详见
@docs/DATABASE.md中的Table: orders->status字段" - 建立索引地图
- 结构化书写文档:总结+标题+核心概念
- 如何组织文档:建立 vibe coding 的工作流程,人来调度任务,任务由项目内外部的 agent 去执行
Vibecoding 流程
-
在 cursor (任意一个 IDE 工具)外部建立强大的 agent,在外部生成 PRD、技术架构、UI/UX 三分文档。
-
在 cursor(任意一个 IDE 工具)内部要维护如下文件夹/文档:
- prd.md、技术架构 structure.md、设计文档 ui&ux.md:这些文档都从外部复制粘贴;
- 分版本的开发计划(位置:/library/develop_plan&history_record/XX 版本开发计划):这个需要 cursor 根据 prompt 和技术架构中的开发阶段划分进行细致拆分,需要落实到可落地的程度;
- 服务索引文档 service.md、数据库文档 database.md、业务流程文档 workfow.md,这三个文档需要 cursor 根据分版本的开发计划生成,后续用于项目管理;
- docs_index.mdc: 对library 等位置的文档创建的索引文档,汇总了所有重要文档,为 cursor 提供整个项目的重要文档地图;
- project_rules.mdc作为 rules,其中的所有内容都会被压缩到 memory 中。
- Action: 作为执行命令 agent prompt,人工触发,是其他文档的生产源头。比如我会要求 cursor,"使用'add_modify_delete.md'流程增加一个 XX 功能"
这套机制的核心就是:人作为智能路由指挥AI完成任务。
一个模型最终能将任务完成到什么程度,取决环境、数据、算法、算力、验证机制。在这套工作流里,环境是rules、数据是library、算法是模型、算力是token是钱、验证机制是测试用例。
我写这套工作流用了3天时间,过程中认知提升了很多。
关于未来的几个认知
时代背景
- 就像软件会吃掉所有硬件能力,层出不穷的任务也会吃掉所有模型优化升级节约出来的token(更低的门槛会吸引更多的用户、刺激更大规模的使用)
- 模型优化没有尽头,幻觉是一个关于性价比的问题。从价格的角度上说,没有"通用"的大模型,只有适合自己的工具,直接用不要等
- 由于模型优化没有尽头,当前上下文工程非常重要,解决这个问题要靠人的认知,也要靠工程优化,比如给文档建立索引地图和压缩总结,要面向AI写文档
价值创造的新方向
- AI给每个人配备了一个可用的工程和算法团队,生产在未来不会成为问题,价值创造也不会在生产环节产生,一切都会回到需求挖掘、营销增长,微笑曲线继续强化
- 个人想在AI领域找工作,一定要去AI无法占据主导、无法一劳永逸解决核心问题的行业,比如投资交易(自带反身性)、科研,还有一些关于人类原始欲望的领域
人的独特价值
推导下去还有很多点,就不继续列举了,我写这一段的目的是想说,无限智能时代已经到了,工具领域已经到了可用的状态,如果想做点事情,必须立刻开始寻找切入点,否则用不了多久很多领域就会被智能和自动化流程吞噬。
在这个过程中,人是有独特意义的:
- 人是需求的本源和最终的落脚点,只有人最懂人,所以人要专注于创意和需求挖掘
- 不要迷信万能模型,每个人必须根据自己的需求来选择工具、与工具结合
Structure 的重要性
智能一定是越来越强的,这会带来信息的泛滥,这个时候structure就变得无比重要。structure代表的是一个人最核心的认知,是唯一可以抵抗熵增的东西。新的教育理念还没成型,我们注定是被AI抛弃的一代人,提早建立对人自身独特性的自信、建立稳定的认知structure,才能有可能有能力驾驭越来越强的人工智能。